
民用AI,本地部署!技嘉4070风魔实测AI生产力
![]() 波导终结者
2023-06-08 08:18
波导终结者
2023-06-08 08:18
大家好,我是波导终结者。
首先想跟大家聊聊最近发展甚快的AI。想必大部分人都不曾想到,AI的发展会如此之快,以至于真的可能影响我们的生活方式。比如最近官媒通报过,AI炸片泛滥,要求大家警惕。现在的技术已经可以做到实时换脸、换声,也就是说陌生人通过AI技术,可以换脸、换声成你认识的人。以前说的要打电话确认已经不管用,甚至视频通话都不管用了。早几年,AI换脸就已经在挑战着司法和伦理的底限,现在只会更糟,因为万一有什么纠纷,照片甚至是视频都不再可信。
鉴于此情况,NVIDIA也是再次大火,市值一度突破万亿美元。现在已经有不少的AI项目已经颇为成熟,甚至可以本地断网只用一张民用显卡来运行。今天就跟大家分享一下最近新入手的显卡,以及一些可以本地利用显卡加速运行的AI项目。事先声明,本文内容侧重于显卡对生产力的加速,不涉及任何不良内容、不良用途的产生和教学。
趁着这次618入手了技嘉4070风魔,主要用来做生产力。挑选理由也比较简单:1.它有12G显存,上代的3080Ti也才12G,至于传说中的4060Ti 16G版,后面再说;2.标准版普遍使用8pin电源接口,更适合部分老机升级;3.功耗比、性价比很高。
先来看看账面数据。4070使用了最新的Ada Lovelace架构,采用AD104-250核心,有5888个CUDA核心,并且L2高速缓存从个前代的4MB提升至36MB,拥有184个TMUS、60个ROPS以及46个光追单元。同时RTX 4070的基础频率达到了1920MHz,Boost频率可达2475MHz。 在显存方面,RTX 4070拥有12GB 192bit位宽的GDDR6X显存,显存速率达到了21Gbps。
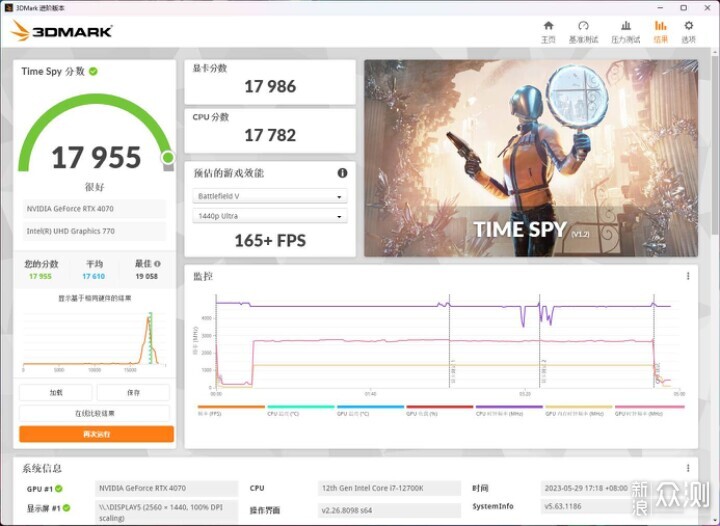
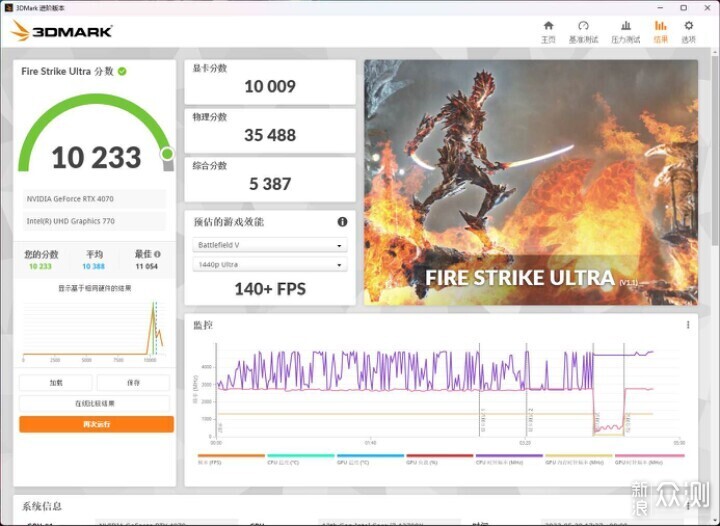
规格上,4070最大的优势是架构和功耗,光追、DLSS3等方面都有优化。游戏性能已经有不少媒体做过实测,这里简单的跑一下3DMARK,TIME SPY 17955分,TIME SPY EXTREME 8360分,FIRE STRIKE EXTREME 20567分,FIRE STRIKE ULTRA 10233分。由于游戏的部分很多人都测过,我打算直奔生产力和AI软件了,毕竟NVIDIA市值暴涨就是因为AI使用显卡加速的普及。而一般理论上来说,干活用的应该上最好的,但现实情况就是,大半的个人甚至公司还是希望捏紧一下预算,挑性价比高的。

正好手上有一块3080Ti,纸面性能肯定是要高于4070的,但考虑到差了好几倍的原价以及功耗,若能达到差不多的生产力效果,4070反而可能是上选。这次的测试平台是:10700K+Z490+3080Ti,WIN10最新版,531.41 Game Ready(懒得重装);以及12700K+Z690+4070,WIN11最新版,531.41 Studio。
关于语音转文字的应用可以追溯到很久很久以前,对于大部分人来说,手机语音转文字是最脸熟的。在干活领域,真正进入大众视野以及实用,还是和短视频分不开,简单来说就是没字幕不看。然而,打过字幕的人都知道,麻烦,耗时。
相关的工具我从很早也就开始用了,比如X易见外,以及民间调用X度API的工具等。但是当大厂进军之后,就没这些工具什么事了。目前就VLOG来说,如果你不担心联网导致的隐密性问题,剪映用起来还是很不错的。
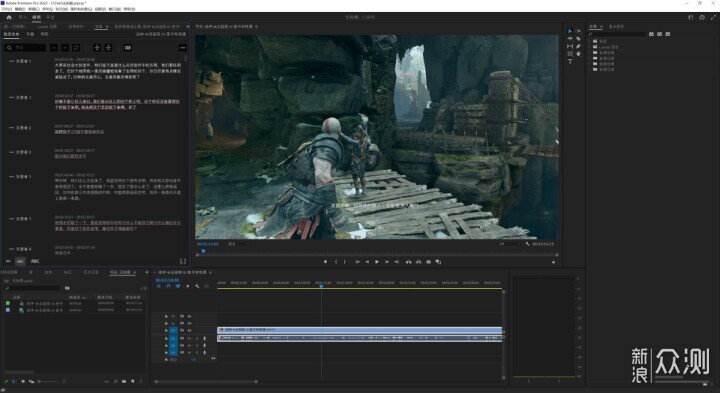
第二个是PR,2022之后的版本也支持语音转文字了,但个人用下来感觉不是很好用。首先它是需要本地模型的,安装包要大上10来G(可精简至剩中英文);其次,断句不舒服,还要比较多的二次操作;第三,离最后生成内嵌或者外挂字幕都还需要额外步骤。
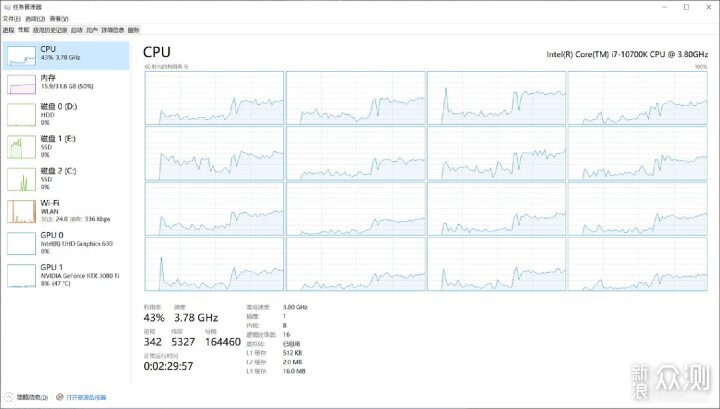
而且目前它的速度还是偏慢,根据资源占用情况可以看到,CPU没有吃满,显卡基本没用到。用我之前自己录的游戏视频实测,1小时的视频需要将近20分钟,速度仅为3倍。
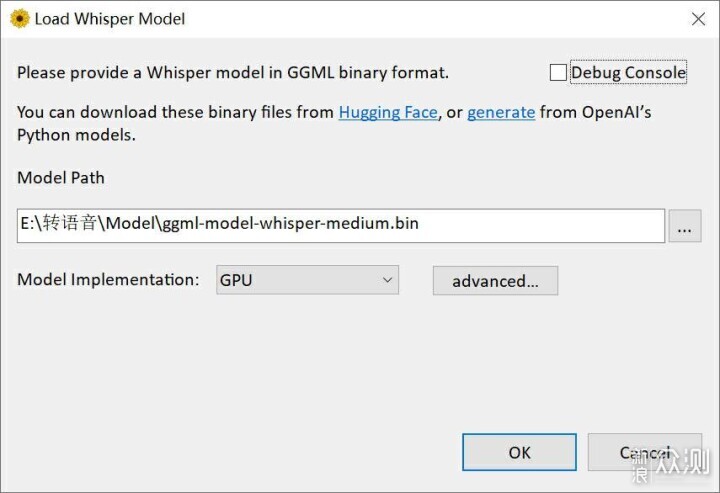
以上2个工具更适合VLOG视频编辑时集成使用,那么如果只是单纯的想要把视频转换成文字,然后输出文本或者SRT字幕,有没有更佳的方案呢?当然是有的。经过我自己一番尝试,由OpenAI开源的Whisper是很不错的方案。首先它是完全离线,依靠本地模型,并且第三方封装的Whisper支持GPU加速,效果也非常不错。
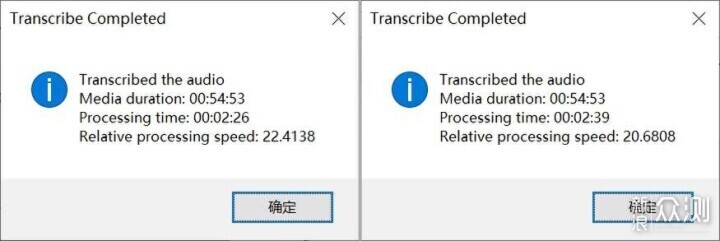
实际操作下来,将近55分钟的视频在3080Ti上仅用时2分26秒转换完成,而4070用时2分39秒,两者都达到了20倍以上的速度。这么一小点的差距,在性价比和能耗比面前不值一提。
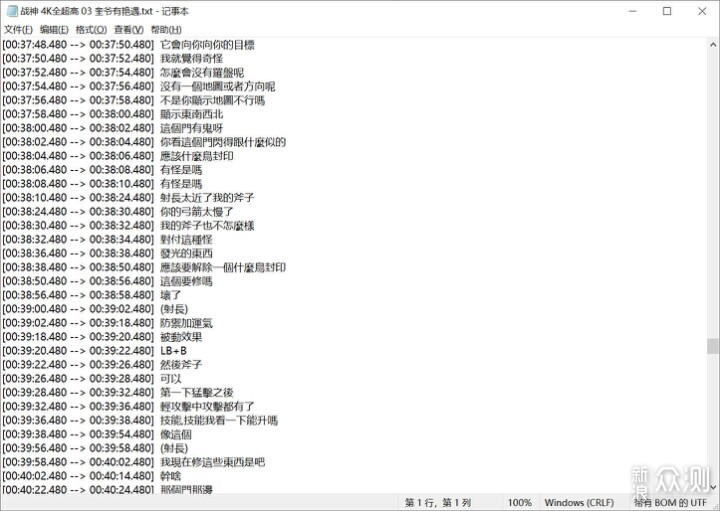
效果方面,一般推荐使用medium模型,但不知为何,出来的文字是繁体中文,使用工具转成简体即可。如果觉得还不满意,可以试试使用large模型,耗时约为medium的2倍,实测速度在12倍速左右。中文medium模型1.5G,large在3G左右,对于生产力来说不痛不痒。而且实际操作的时候,我发现中文里夹杂的英文其实也可以识别出来,比如图里的“LB+B”,是我在实况解说时说到的手柄操作,其他的常用单词,比如F开头或者S开头的基本也可以识别出来。
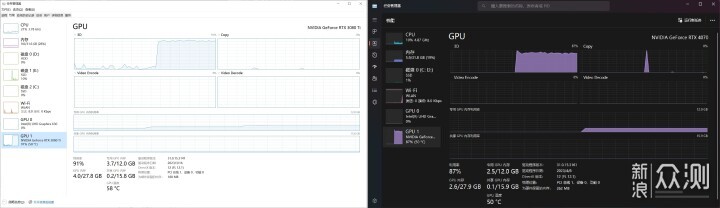
实际占用方面,虽然官方推荐16GB显存,但我用的时候分别只吃掉了3.7G和2.5G显存,12G应该是够的,两张显卡的3D占用都在90%左右浮动。

令我觉得有点惊喜的是4070的温度,我看任务管理器,在50和60多度之间来回跳,一开始以为是显示错误。用手摸了一下,背板竟然也不是很烫,可以把手指一直放在上面。仔细一想,又看了一下风扇,恍然大悟。现在的显卡都有风扇智能启停,默认好像是50度以下不转,而4070的功耗和发热控制得更出色,刚好卡在50度左右,不转的时候温度迅速上升,然后风扇转起来又降到了50度以下,又不转了。哦,还有一点忘了提,这卡只需单8pin供电。
另外,我还试了一下纯CPU识别,不知道是不是这个工具封装的时候只做了GPU的部分。如果强制只使用CPU的话,速度极慢,出不了结果,我甚至弄了个几分钟的小视频进去,也一直卡着进度条,而CPU占用率一直是满的。最后我又去弄了原始的python程序试了一下,10分钟的视频花了我差不多1小时,人直接傻了。简单换算的话,显卡的速度为CPU的120倍左右。
总结一下,如果你只是做VLOG,几分钟视频打打字幕,不介意联网,那么直接扔剪映里面就行。而如果有生产力需求,有比较大数量或者时长的资源需要处理,那么Whisper是目前的首选。它不仅可以通过脚本单独运行,或者使用封装好的EXE,也可以直接集成源代码实现更多复杂的功能。显卡加速效果明显,在4070上可以以1:20以上的速度运行。
对于更多老……朋友来说,可能最蠢蠢欲动的是AI绘画了。鉴于用途不同,本文不使用额外的模型,不生成真人照片,只讨论显卡加速效果。这里偷懒,直接使用了基于stable diffusion的第三方整合包,可以自由切换CPU或者显卡。
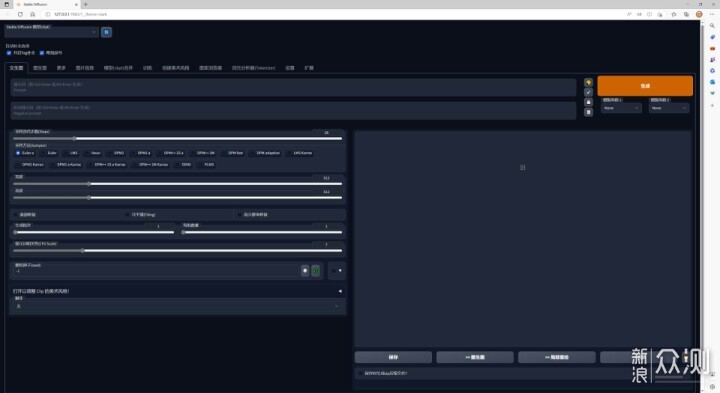
这东西的参数非常多的,本文并非AI绘画效果教程,所以不多赘述。模型貌似是以块为单独生成的,所以分辨率并不能任意设置。
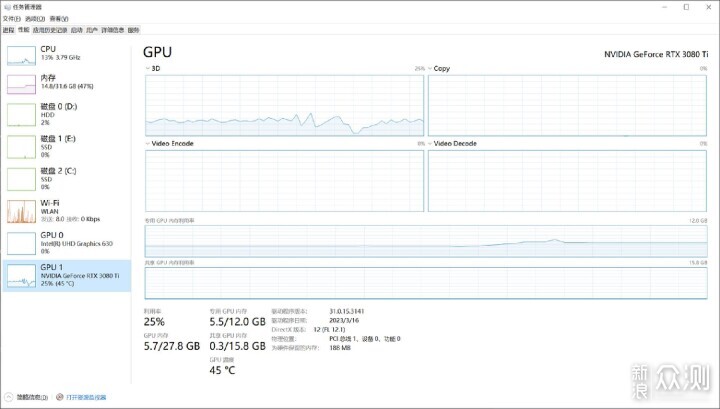
实测的时候,CPU工作时资源吃到70%-80%左右,并未跑满。显卡只有3D吃到25%左右,显存还剩一半有余,甚至连风扇都懒得转。AI绘画是多次迭代的,出现这种情况并不意外。

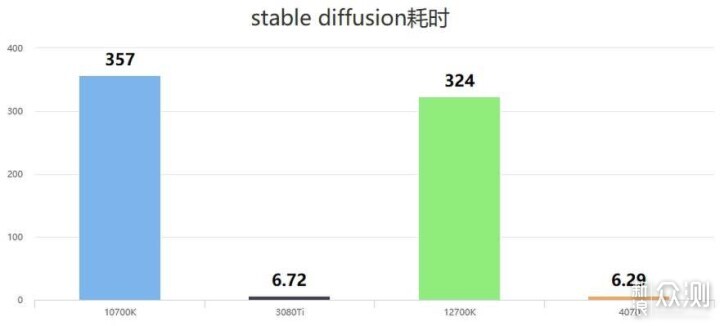
我让引擎生成一张显卡,10700K耗时5分57秒,3080Ti耗时6秒72,12700K耗时5分24秒,4070耗时6秒29。请注意,本次主要探讨的是显卡在同等设置和质量下的速度优势,所以并未使用额外的模型,也不生成真人图片。
总的来看,在AI绘画时,4070/3080Ti的速度都在CPU的50倍以上,如果是生产力用途的话,往往需要生成非常大量的图片从中挑选,这时候提升还是相当可观的。不过,在尝试生成1920级别分辨率的时候,两张12GB显存的显卡都爆了显存,虽然可以通过--lowvram参数缓解,但是速度又慢了。所以对这方面生产力要求高的用户,还得挑选更大显存的型号,比如24GB显存的4090。
如果是玩电脑比较早的朋友,又有稍微玩一下音频处理之类的,可能会对“消音伴奏”有点印象。以前,一首歌曲,如果没有官方的伴奏,而一般人又没有足够的乐理能力,是无法弄出质量好点的伴奏的。普通用户只能用消音的方式,说白了就是把歌曲的左右声道反相,那么一般来说,人声左右声道均匀,反相之后抵消,留下大部分伴奏。然而,这种方式的效果全看脸,有的歌曲能达到90%的效果,也有的人声基本还在,主要伴奏却被消得参差不齐了。如果你去KTV有唱过所谓的盗版歌曲,感觉伴奏很怪,那有很大概率就是老式的消音伴奏弄的。
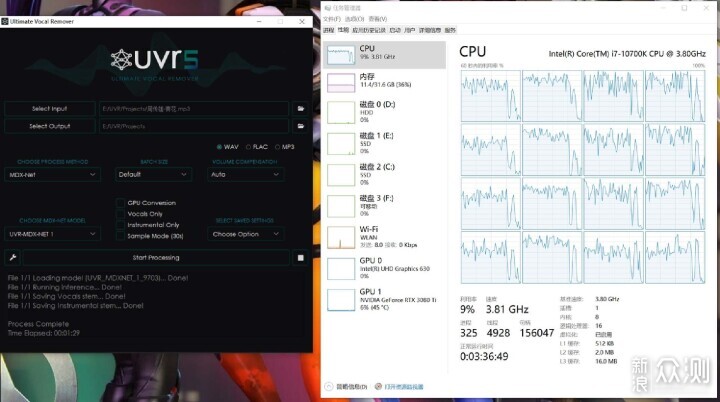
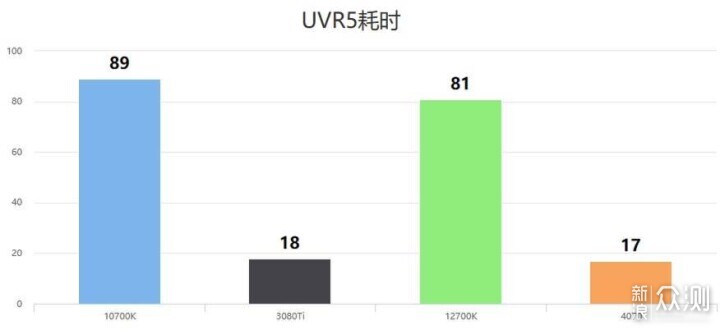
然而,随着近几年AI的流行,使用AI配合模型对音频进行人声与伴奏的高质量分离成为了可能。UVR5这款软件现在的效果已经非常不错,并且不管有没有显卡,都可以使用。这里先使用CPU进行处理,耗时1分29秒。
如果仅是对一首3-5分钟的歌曲进行处理,那么CPU的速度也还可以忍受,当然有显卡的话快4-5倍那是更好的。而严格来说,UVR5不仅仅是对歌曲进行处理,而是分离人声。举个例子,比如现在有部动画,你想给它做配音,但是找得到背景音源吗?几乎找不到。不用说个人了,以前我就看过不少因为没有靠谱音源而效果极其糟糕的国配动画,比如七龙珠Z和灌篮高手的其中某些集数,相信看过的朋友都有印象。

关于效果,我只使用了默认的UVR-MDX-NET 1模型,结论就是两个字:牛逼!伴奏干干净净,一点人声都没有。而人声部分一样干干净净,连混音和和声都全在。如果硬要说缺点的话,那就是伴奏没和声了,这种基于模型的分离人声与乐器很容易,但分离主唱与和声却很难。如果你有比较大批量或者时长的音频需要分离人声,搞块显卡能把速度快5倍也是很舒服的事情。

因为涉及到版权和炸片风险,这里只粗浅聊聊。目前AI歌手的做法就是先用刚才提到的UVR5之类的把人声分离出来,作为模型训练,再用模型去唱歌,拟真度已经可以达到95%,除了“没感情”之外,真的是随便暴打初音洛天依。并且整合在一起的话,就可以实时换声。而换脸的前身,比如Facerig之类的以前也流行过,前几年也已经有非实时换脸技术出现,也经常被用到动作片上,你看到的“XX明星流出”基本上都是换脸的。但最近技术继续发展,已经可以实现实时换脸甚至“换人”,也即连全身肢体动作一起换。
我只能说,我很担心,但无能为力。这技术被滥用的后果非常严重,而目前全球行业内都缺乏有效的技术和法律手段去应对。我不担心显卡涨价,我很担心炸片泛滥,伪造的图片和视频泛滥。
AI视频放大本质上和AI图片放大是同一回事,所以放到一起说。那些AI旧照片修复啥的同理。以前,在DLSS出现之前,有人问我说视频能放大吗,马赛克能去除吗,我都很肯定的说:不能,因为缺失的细节是什么,谁也不知道。
现在,这个说法仍然没有问题,但是,AI可以把细节补齐到,让人看起来“觉得就是原片”。也即AI放大补齐的当然不是原始细节,但是合情合理,让人类看起来觉得没有差别。
这方面目前最流行的软件是Topaz Video AI,最新版本3.0.5,支持各类显卡加速。
这里我用自己录的塞尔达1080P视频来试,放大到3840x2160,默认模型和效果,不做其他处理。可以看到,纯CPU干活时,每秒只有0.2帧,这个速度非常简直无语。而且可以看到,大核没干满,小核没在干。
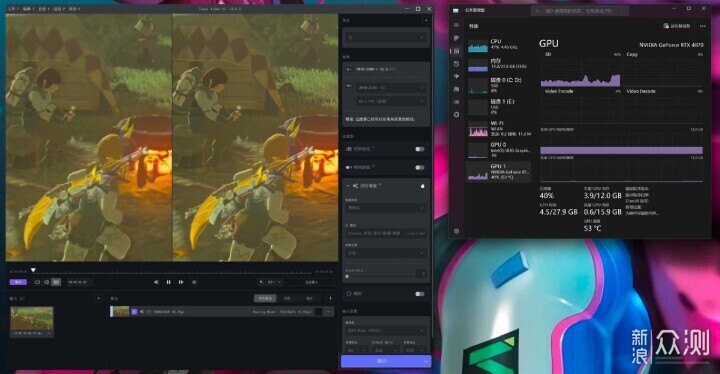
使用4070干活时,速度“飙升”了20多倍来到3帧左右,在2.5-3.3范围内浮动,真是可喜可贺。软件也提供“All GPUs”的选项,但想也知道CPU核显独显同时干到满几乎不可能,实测与独显加速并无区别。鉴于速度太慢,我觉得AI视频放大目前并不具有民用意义上的泛用性,更多的是用来偶尔给什么老旧MV或者你懂的视频翻个新,或者商业上砸一堆机器来翻新个什么4K电视剧之类的。
之前我夸过开源软件的生命力与更新速度,这不,FFmpeg与OBS已经第一时间跟进了AV1的显卡编码加速。目前40系的N卡,INTEL的Arc独显和最新的AMD 7000系均已搭载支持AV1硬编码(注意不是解码)。根据众多测试,目前N卡的Ada Lovelace架构搭载的第八代NVENC效果最好。
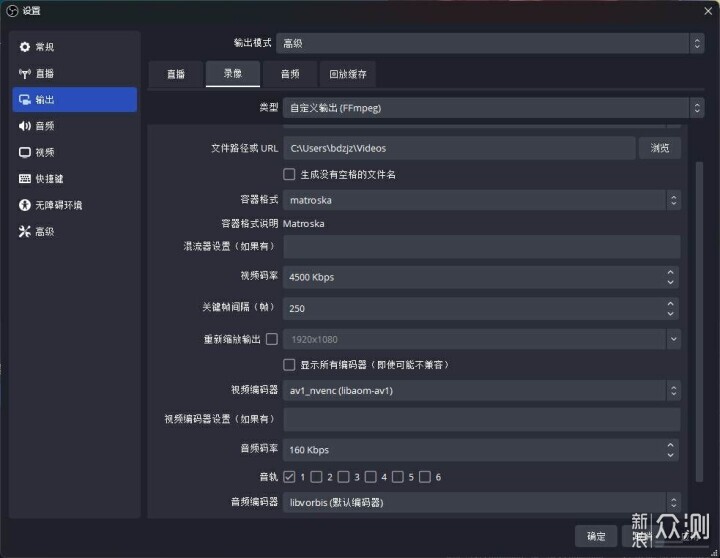
我用最新版OBS试了一下,首先H265和AV1编码在国内无法开启,只有某404直播站支持。这里我用本地录像做测试,只需要把输出模式设为高级,录像里选择自定义输出,编码器找到av1_nvenc即可。
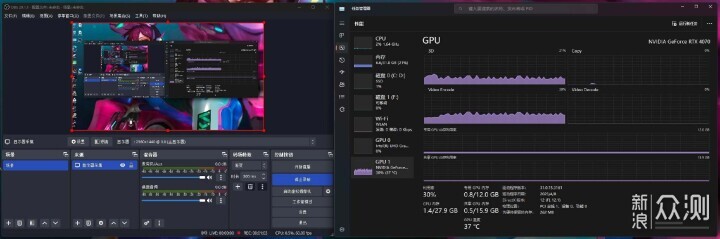
测试时接的是2560x1440显示器,OBS的分辨率也基于此,编码占用显卡Video Encode约30%,实时编码4K肯定也是绰绰有余。此时CPU占用仅2%,约等于放假。录完之后播放视频验证,无任何问题。
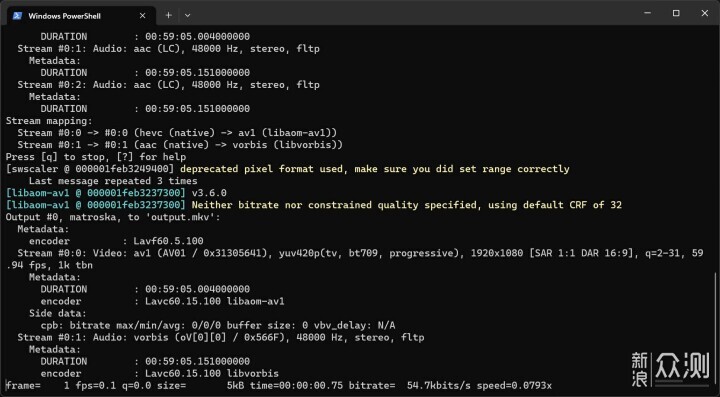
至于非直播的AV1编码,也即视频压制,首先我使用最新版本的FFmpeg进行CPU软压,速度不到0.1倍,可以认为基本不可用。其实诸多编码器初期不完善时都是这样,包括H264早期用CPU软压也是这么慢,当时不少的压片大佬也经历过0.1倍速压片的日子,向压片前辈们致敬。
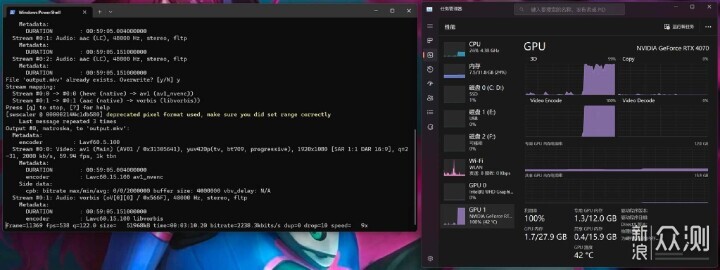
使用av1_nvenc压制时,可喜可贺,速度直接上了9倍,并且从任务管理器中可以看到,3D和Video Encode基本都吃满了。生产力的时候,吃越满当然是越高兴的了。
那么,目前AV1硬编码已经完全可用,但目前只有命令行最靠谱,只待各个GUI跟进。当然,在网上我也看到一些营销号乱吹,说什么市面上的GUI有多少多少都已经支持AV1硬编码,还特地拿我常用的ShanaEncoder举例。那么我要打脸了:ShanaEncoder最新版本5.3.1.1是去年2月发布的,根本不可能支持,试都不用试(当然我试过)。
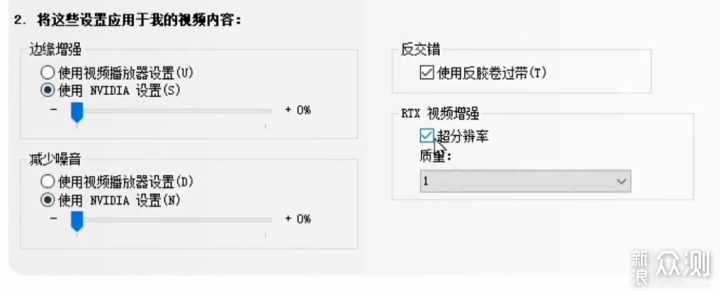
在新技术的探索上,NVIDIA确实一直都处于领先的地位,包括之前3D游戏里的抗锯齿、DSR等方案,以及G-Sync、DLSS、Reflex等。这其中也有一些比较轻度的AI应用,这里也跟大家盘点一下。最近30和40系的显卡是支持了VSR视频增强技术,说白了就是插值分辨率,目前Chrome和Edge浏览器,以及VLC本地播放支持。我实测观感确实有所提升,但是并不大,优于单纯的锐化,劣于DLSS和Topaz Video AI(废话),并且对显卡的占用也不小,个人觉得没啥用,不推荐开。
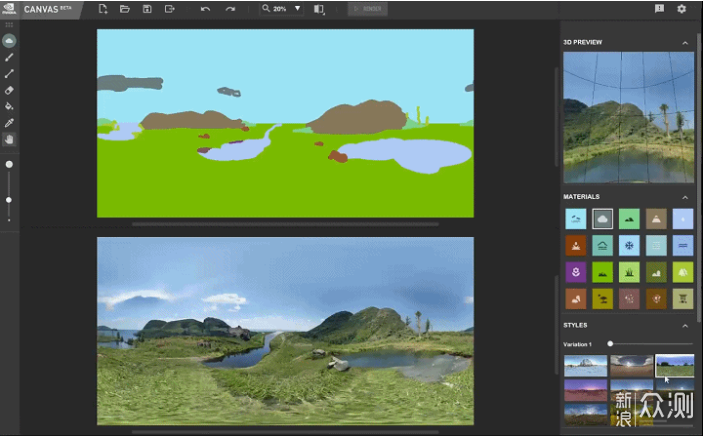
第二个是NVIDIA Canvas,AI风景画。用户简单的画上几笔,由AI来生成相应的风景画。由于只能输出风景画,没什么人用,但如果有需求并且有一定绘画功底的人用可能有奇效。最近1.4版本甚至还更新了导出3D环境贴图的功能……
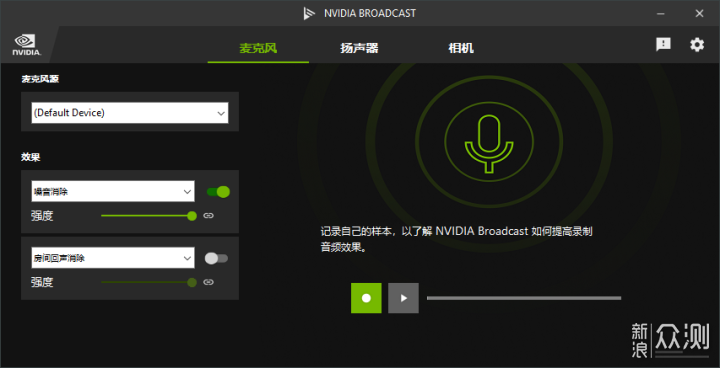
比较实用的是BROADCAST,包括很实用的麦克风AI降噪和相机智能抠图。值得表扬的是,NVIDIA将SDK做了开放,OBS以及很多外设厂商都在自己的软件内集成了这些功能。

总的来看,电子产品买新不买旧的说法还是有一定道理的。4070新的架构和工艺使得它比前代准旗舰卡更有性价比,这张技嘉风魔4070是系列最基础的版本,然而无论是做工用料还是实际表现都很出色。

正逆3风扇加上非常下料的散热配置,本身却只需要单8pin供电以及不到200W的功耗,干活时安静又省电,温度也压得很理想,风扇经常都懒得转。想像一下,如果不是一台机子,而是有一定需求的公司采购40台,一天24小时不停地干活(比如转码之类的,不是挖矿哦),那么一年省下的电费都能买多少张显卡了。

挡板这里也是有个小设计,可以看到做了一个小弯折,这样螺丝拧下去之后固定性很好。再加上4070本身大小和重量适中,应该不需要显卡支架。其他的角度拍了拍,感觉也没啥好看的了,就是插上,干活!
感谢大家的点赞,专业硬核内容,请关注波导终结者,有些正文不方便展示的内容,可以评论里聊聊。我们下期再见。
PS:你关注或者喜欢的萌妹或者大乃Vtuber有99%都是抠脚大汉通过AI之类的技术变的。别问我为什么知道,一般人我不告诉他……
大家好,我是波导终结者。
首先想跟大家聊聊最近发展甚快的AI。想必大部分人都不曾想到,AI的发展会如此之快,以至于真的可能影响我们的生活方式。比如最近官媒通报过,AI炸片泛滥,要求大家警惕。现在的技术已经可以做到实时换脸、换声,也就是说陌生人通过AI技术,可以换脸、换声成你认识的人。以前说的要打电话确认已经不管用,甚至视频通话都不管用了。早几年,AI换脸就已经在挑战着司法和伦理的底限,现在只会更糟,因为万一有什么纠纷,照片甚至是视频都不再可信。
鉴于此情况,NVIDIA也是再次大火,市值一度突破万亿美元。现在已经有不少的AI项目已经颇为成熟,甚至可以本地断网只用一张民用显卡来运行。今天就跟大家分享一下最近新入手的显卡,以及一些可以本地利用显卡加速运行的AI项目。事先声明,本文内容侧重于显卡对生产力的加速,不涉及任何不良内容、不良用途的产生和教学。
趁着这次618入手了技嘉4070风魔,主要用来做生产力。挑选理由也比较简单:1.它有12G显存,上代的3080Ti也才12G,至于传说中的4060Ti 16G版,后面再说;2.标准版普遍使用8pin电源接口,更适合部分老机升级;3.功耗比、性价比很高。
先来看看账面数据。4070使用了最新的Ada Lovelace架构,采用AD104-250核心,有5888个CUDA核心,并且L2高速缓存从个前代的4MB提升至36MB,拥有184个TMUS、60个ROPS以及46个光追单元。同时RTX 4070的基础频率达到了1920MHz,Boost频率可达2475MHz。 在显存方面,RTX 4070拥有12GB 192bit位宽的GDDR6X显存,显存速率达到了21Gbps。
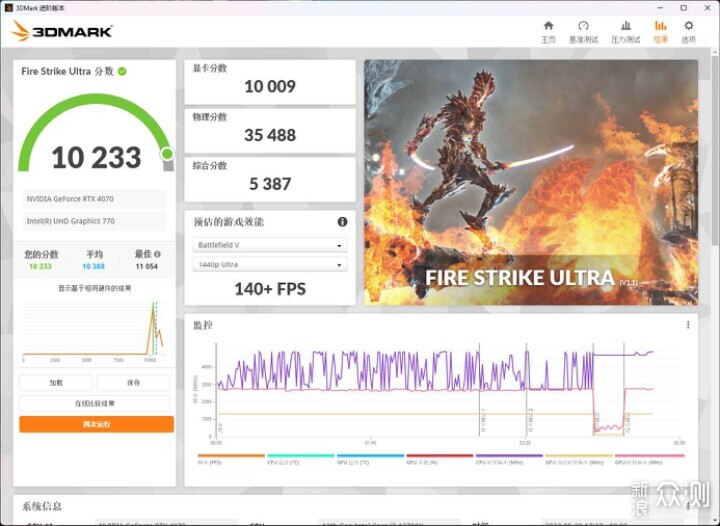
规格上,4070最大的优势是架构和功耗,光追、DLSS3等方面都有优化。游戏性能已经有不少媒体做过实测,这里简单的跑一下3DMARK,TIME SPY 17955分,TIME SPY EXTREME 8360分,FIRE STRIKE EXTREME 20567分,FIRE STRIKE ULTRA 10233分。由于游戏的部分很多人都测过,我打算直奔生产力和AI软件了,毕竟NVIDIA市值暴涨就是因为AI使用显卡加速的普及。而一般理论上来说,干活用的应该上最好的,但现实情况就是,大半的个人甚至公司还是希望捏紧一下预算,挑性价比高的。
正好手上有一块3080Ti,纸面性能肯定是要高于4070的,但考虑到差了好几倍的原价以及功耗,若能达到差不多的生产力效果,4070反而可能是上选。这次的测试平台是:10700K+Z490+3080Ti,WIN10最新版,531.41 Game Ready(懒得重装);以及12700K+Z690+4070,WIN11最新版,531.41 Studio。
关于语音转文字的应用可以追溯到很久很久以前,对于大部分人来说,手机语音转文字是最脸熟的。在干活领域,真正进入大众视野以及实用,还是和短视频分不开,简单来说就是没字幕不看。然而,打过字幕的人都知道,麻烦,耗时。
相关的工具我从很早也就开始用了,比如X易见外,以及民间调用X度API的工具等。但是当大厂进军之后,就没这些工具什么事了。目前就VLOG来说,如果你不担心联网导致的隐密性问题,剪映用起来还是很不错的。
第二个是PR,2022之后的版本也支持语音转文字了,但个人用下来感觉不是很好用。首先它是需要本地模型的,安装包要大上10来G(可精简至剩中英文);其次,断句不舒服,还要比较多的二次操作;第三,离最后生成内嵌或者外挂字幕都还需要额外步骤。
而且目前它的速度还是偏慢,根据资源占用情况可以看到,CPU没有吃满,显卡基本没用到。用我之前自己录的游戏视频实测,1小时的视频需要将近20分钟,速度仅为3倍。
以上2个工具更适合VLOG视频编辑时集成使用,那么如果只是单纯的想要把视频转换成文字,然后输出文本或者SRT字幕,有没有更佳的方案呢?当然是有的。经过我自己一番尝试,由OpenAI开源的Whisper是很不错的方案。首先它是完全离线,依靠本地模型,并且第三方封装的Whisper支持GPU加速,效果也非常不错。
实际操作下来,将近55分钟的视频在3080Ti上仅用时2分26秒转换完成,而4070用时2分39秒,两者都达到了20倍以上的速度。这么一小点的差距,在性价比和能耗比面前不值一提。
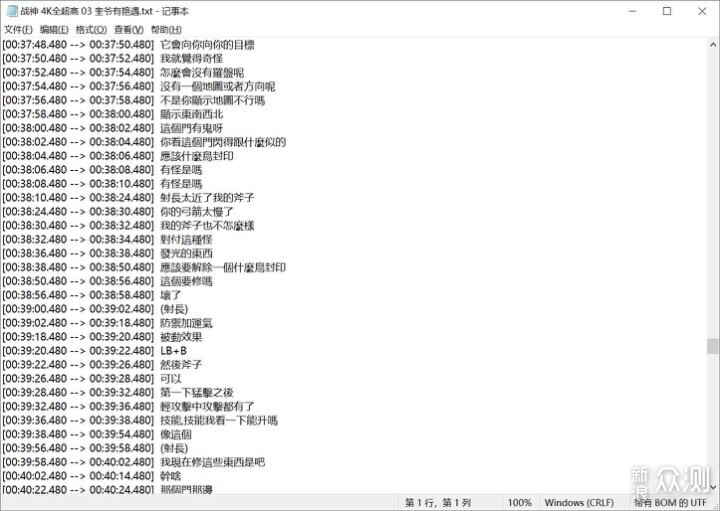
效果方面,一般推荐使用medium模型,但不知为何,出来的文字是繁体中文,使用工具转成简体即可。如果觉得还不满意,可以试试使用large模型,耗时约为medium的2倍,实测速度在12倍速左右。中文medium模型1.5G,large在3G左右,对于生产力来说不痛不痒。而且实际操作的时候,我发现中文里夹杂的英文其实也可以识别出来,比如图里的“LB+B”,是我在实况解说时说到的手柄操作,其他的常用单词,比如F开头或者S开头的基本也可以识别出来。
实际占用方面,虽然官方推荐16GB显存,但我用的时候分别只吃掉了3.7G和2.5G显存,12G应该是够的,两张显卡的3D占用都在90%左右浮动。
令我觉得有点惊喜的是4070的温度,我看任务管理器,在50和60多度之间来回跳,一开始以为是显示错误。用手摸了一下,背板竟然也不是很烫,可以把手指一直放在上面。仔细一想,又看了一下风扇,恍然大悟。现在的显卡都有风扇智能启停,默认好像是50度以下不转,而4070的功耗和发热控制得更出色,刚好卡在50度左右,不转的时候温度迅速上升,然后风扇转起来又降到了50度以下,又不转了。哦,还有一点忘了提,这卡只需单8pin供电。
另外,我还试了一下纯CPU识别,不知道是不是这个工具封装的时候只做了GPU的部分。如果强制只使用CPU的话,速度极慢,出不了结果,我甚至弄了个几分钟的小视频进去,也一直卡着进度条,而CPU占用率一直是满的。最后我又去弄了原始的python程序试了一下,10分钟的视频花了我差不多1小时,人直接傻了。简单换算的话,显卡的速度为CPU的120倍左右。
总结一下,如果你只是做VLOG,几分钟视频打打字幕,不介意联网,那么直接扔剪映里面就行。而如果有生产力需求,有比较大数量或者时长的资源需要处理,那么Whisper是目前的首选。它不仅可以通过脚本单独运行,或者使用封装好的EXE,也可以直接集成源代码实现更多复杂的功能。显卡加速效果明显,在4070上可以以1:20以上的速度运行。
对于更多老……朋友来说,可能最蠢蠢欲动的是AI绘画了。鉴于用途不同,本文不使用额外的模型,不生成真人照片,只讨论显卡加速效果。这里偷懒,直接使用了基于stable diffusion的第三方整合包,可以自由切换CPU或者显卡。
这东西的参数非常多的,本文并非AI绘画效果教程,所以不多赘述。模型貌似是以块为单独生成的,所以分辨率并不能任意设置。
实测的时候,CPU工作时资源吃到70%-80%左右,并未跑满。显卡只有3D吃到25%左右,显存还剩一半有余,甚至连风扇都懒得转。AI绘画是多次迭代的,出现这种情况并不意外。

我让引擎生成一张显卡,10700K耗时5分57秒,3080Ti耗时6秒72,12700K耗时5分24秒,4070耗时6秒29。请注意,本次主要探讨的是显卡在同等设置和质量下的速度优势,所以并未使用额外的模型,也不生成真人图片。
总的来看,在AI绘画时,4070/3080Ti的速度都在CPU的50倍以上,如果是生产力用途的话,往往需要生成非常大量的图片从中挑选,这时候提升还是相当可观的。不过,在尝试生成1920级别分辨率的时候,两张12GB显存的显卡都爆了显存,虽然可以通过--lowvram参数缓解,但是速度又慢了。所以对这方面生产力要求高的用户,还得挑选更大显存的型号,比如24GB显存的4090。
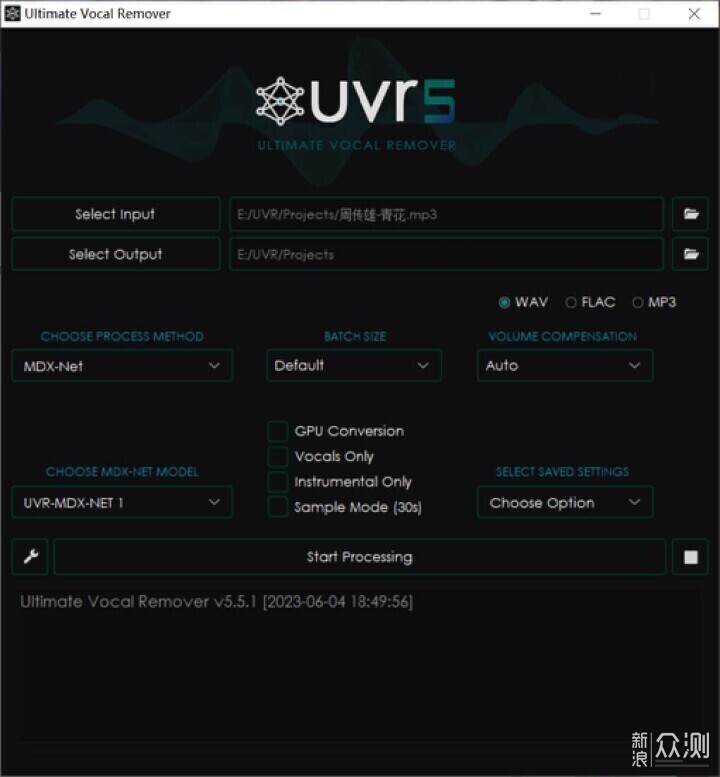
如果是玩电脑比较早的朋友,又有稍微玩一下音频处理之类的,可能会对“消音伴奏”有点印象。以前,一首歌曲,如果没有官方的伴奏,而一般人又没有足够的乐理能力,是无法弄出质量好点的伴奏的。普通用户只能用消音的方式,说白了就是把歌曲的左右声道反相,那么一般来说,人声左右声道均匀,反相之后抵消,留下大部分伴奏。然而,这种方式的效果全看脸,有的歌曲能达到90%的效果,也有的人声基本还在,主要伴奏却被消得参差不齐了。如果你去KTV有唱过所谓的盗版歌曲,感觉伴奏很怪,那有很大概率就是老式的消音伴奏弄的。
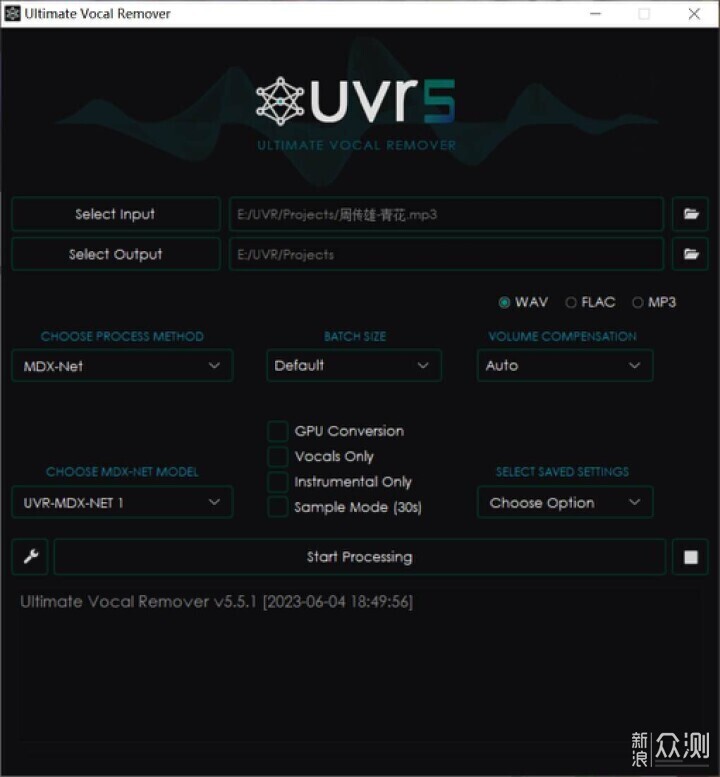
然而,随着近几年AI的流行,使用AI配合模型对音频进行人声与伴奏的高质量分离成为了可能。UVR5这款软件现在的效果已经非常不错,并且不管有没有显卡,都可以使用。这里先使用CPU进行处理,耗时1分29秒。
如果仅是对一首3-5分钟的歌曲进行处理,那么CPU的速度也还可以忍受,当然有显卡的话快4-5倍那是更好的。而严格来说,UVR5不仅仅是对歌曲进行处理,而是分离人声。举个例子,比如现在有部动画,你想给它做配音,但是找得到背景音源吗?几乎找不到。不用说个人了,以前我就看过不少因为没有靠谱音源而效果极其糟糕的国配动画,比如七龙珠Z和灌篮高手的其中某些集数,相信看过的朋友都有印象。

关于效果,我只使用了默认的UVR-MDX-NET 1模型,结论就是两个字:牛逼!伴奏干干净净,一点人声都没有。而人声部分一样干干净净,连混音和和声都全在。如果硬要说缺点的话,那就是伴奏没和声了,这种基于模型的分离人声与乐器很容易,但分离主唱与和声却很难。如果你有比较大批量或者时长的音频需要分离人声,搞块显卡能把速度快5倍也是很舒服的事情。

因为涉及到版权和炸片风险,这里只粗浅聊聊。目前AI歌手的做法就是先用刚才提到的UVR5之类的把人声分离出来,作为模型训练,再用模型去唱歌,拟真度已经可以达到95%,除了“没感情”之外,真的是随便暴打初音洛天依。并且整合在一起的话,就可以实时换声。而换脸的前身,比如Facerig之类的以前也流行过,前几年也已经有非实时换脸技术出现,也经常被用到动作片上,你看到的“XX明星流出”基本上都是换脸的。但最近技术继续发展,已经可以实现实时换脸甚至“换人”,也即连全身肢体动作一起换。
我只能说,我很担心,但无能为力。这技术被滥用的后果非常严重,而目前全球行业内都缺乏有效的技术和法律手段去应对。我不担心显卡涨价,我很担心炸片泛滥,伪造的图片和视频泛滥。
AI视频放大本质上和AI图片放大是同一回事,所以放到一起说。那些AI旧照片修复啥的同理。以前,在DLSS出现之前,有人问我说视频能放大吗,马赛克能去除吗,我都很肯定的说:不能,因为缺失的细节是什么,谁也不知道。
现在,这个说法仍然没有问题,但是,AI可以把细节补齐到,让人看起来“觉得就是原片”。也即AI放大补齐的当然不是原始细节,但是合情合理,让人类看起来觉得没有差别。
这方面目前最流行的软件是Topaz Video AI,最新版本3.0.5,支持各类显卡加速。
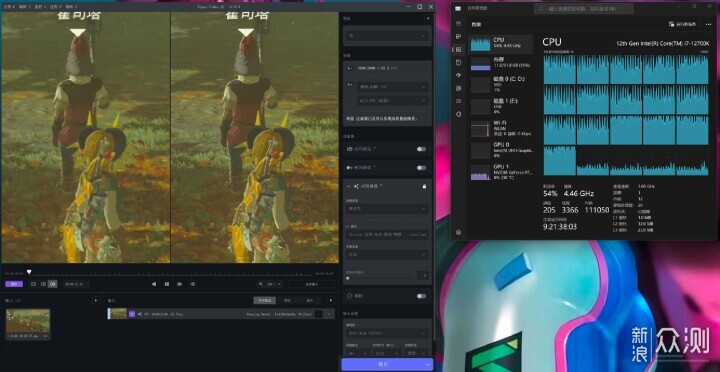
这里我用自己录的塞尔达1080P视频来试,放大到3840x2160,默认模型和效果,不做其他处理。可以看到,纯CPU干活时,每秒只有0.2帧,这个速度非常简直无语。而且可以看到,大核没干满,小核没在干。
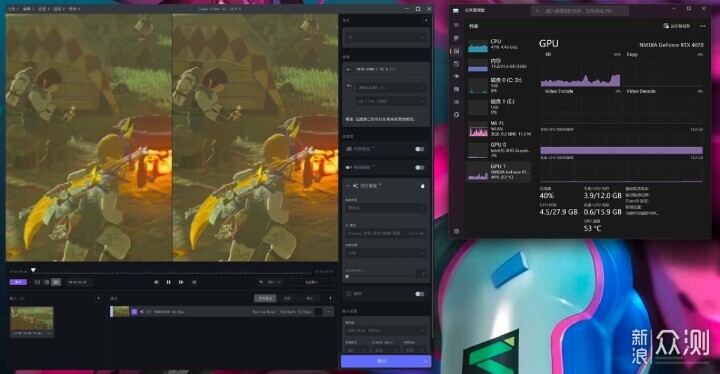
使用4070干活时,速度“飙升”了20多倍来到3帧左右,在2.5-3.3范围内浮动,真是可喜可贺。软件也提供“All GPUs”的选项,但想也知道CPU核显独显同时干到满几乎不可能,实测与独显加速并无区别。鉴于速度太慢,我觉得AI视频放大目前并不具有民用意义上的泛用性,更多的是用来偶尔给什么老旧MV或者你懂的视频翻个新,或者商业上砸一堆机器来翻新个什么4K电视剧之类的。
之前我夸过开源软件的生命力与更新速度,这不,FFmpeg与OBS已经第一时间跟进了AV1的显卡编码加速。目前40系的N卡,INTEL的Arc独显和最新的AMD 7000系均已搭载支持AV1硬编码(注意不是解码)。根据众多测试,目前N卡的Ada Lovelace架构搭载的第八代NVENC效果最好。
我用最新版OBS试了一下,首先H265和AV1编码在国内无法开启,只有某404直播站支持。这里我用本地录像做测试,只需要把输出模式设为高级,录像里选择自定义输出,编码器找到av1_nvenc即可。
测试时接的是2560x1440显示器,OBS的分辨率也基于此,编码占用显卡Video Encode约30%,实时编码4K肯定也是绰绰有余。此时CPU占用仅2%,约等于放假。录完之后播放视频验证,无任何问题。
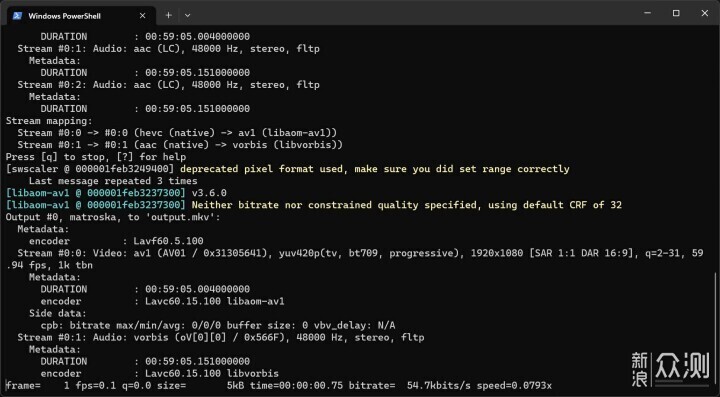
至于非直播的AV1编码,也即视频压制,首先我使用最新版本的FFmpeg进行CPU软压,速度不到0.1倍,可以认为基本不可用。其实诸多编码器初期不完善时都是这样,包括H264早期用CPU软压也是这么慢,当时不少的压片大佬也经历过0.1倍速压片的日子,向压片前辈们致敬。
使用av1_nvenc压制时,可喜可贺,速度直接上了9倍,并且从任务管理器中可以看到,3D和Video Encode基本都吃满了。生产力的时候,吃越满当然是越高兴的了。
那么,目前AV1硬编码已经完全可用,但目前只有命令行最靠谱,只待各个GUI跟进。当然,在网上我也看到一些营销号乱吹,说什么市面上的GUI有多少多少都已经支持AV1硬编码,还特地拿我常用的ShanaEncoder举例。那么我要打脸了:ShanaEncoder最新版本5.3.1.1是去年2月发布的,根本不可能支持,试都不用试(当然我试过)。
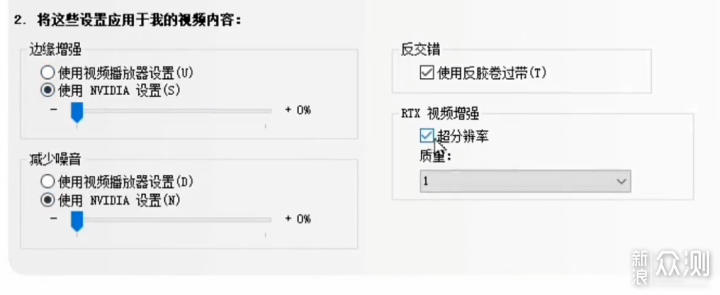
在新技术的探索上,NVIDIA确实一直都处于领先的地位,包括之前3D游戏里的抗锯齿、DSR等方案,以及G-Sync、DLSS、Reflex等。这其中也有一些比较轻度的AI应用,这里也跟大家盘点一下。最近30和40系的显卡是支持了VSR视频增强技术,说白了就是插值分辨率,目前Chrome和Edge浏览器,以及VLC本地播放支持。我实测观感确实有所提升,但是并不大,优于单纯的锐化,劣于DLSS和Topaz Video AI(废话),并且对显卡的占用也不小,个人觉得没啥用,不推荐开。
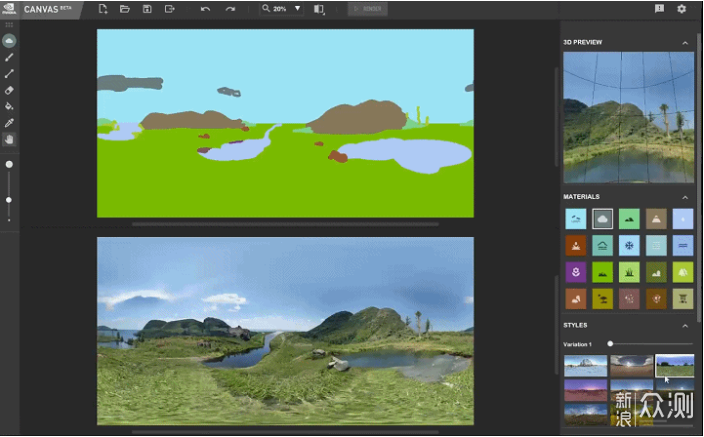
第二个是NVIDIA Canvas,AI风景画。用户简单的画上几笔,由AI来生成相应的风景画。由于只能输出风景画,没什么人用,但如果有需求并且有一定绘画功底的人用可能有奇效。最近1.4版本甚至还更新了导出3D环境贴图的功能……
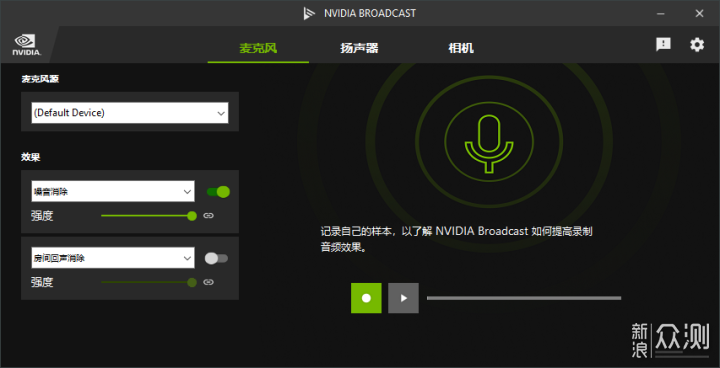
比较实用的是BROADCAST,包括很实用的麦克风AI降噪和相机智能抠图。值得表扬的是,NVIDIA将SDK做了开放,OBS以及很多外设厂商都在自己的软件内集成了这些功能。
总的来看,电子产品买新不买旧的说法还是有一定道理的。4070新的架构和工艺使得它比前代准旗舰卡更有性价比,这张技嘉风魔4070是系列最基础的版本,然而无论是做工用料还是实际表现都很出色。

正逆3风扇加上非常下料的散热配置,本身却只需要单8pin供电以及不到200W的功耗,干活时安静又省电,温度也压得很理想,风扇经常都懒得转。想像一下,如果不是一台机子,而是有一定需求的公司采购40台,一天24小时不停地干活(比如转码之类的,不是挖矿哦),那么一年省下的电费都能买多少张显卡了。
挡板这里也是有个小设计,可以看到做了一个小弯折,这样螺丝拧下去之后固定性很好。再加上4070本身大小和重量适中,应该不需要显卡支架。其他的角度拍了拍,感觉也没啥好看的了,就是插上,干活!
感谢大家的点赞,专业硬核内容,请关注波导终结者,有些正文不方便展示的内容,可以评论里聊聊。我们下期再见。
PS:你关注或者喜欢的萌妹或者大乃Vtuber有99%都是抠脚大汉通过AI之类的技术变的。别问我为什么知道,一般人我不告诉他……
关注官方微博 微博
关注官方微信

Copyright © 1996-2024 SINA Corporation, All Rights Reserved 新浪公司 版权所有







